Appendix
Code Samples
The LidarHub has open TCP ports which stream the occupancy and object data. The user can listen to this data and create custom logic to fit their needs.
TCP Server Heartbeat Setup
The current TCP stream stops outputting data when there are no objects in the scene. When there are no objects in the scene for an extended period of time, the recv() call may timeout. It is recommended to configure a heartbeat message for the tcp_servers.
The heartbeat message only outputs when there are no objects present in the scene (when listening to the object_list), or when there are no objects present in any event zone (when listening to the occupations). The below LidarHub setting was used for the examples. Note that the heartbeat_message can be modified to a different message.
"tcp_servers": [
{
"source": "object_list",
"port": 3302,
"data_hertz": 1,
"transmit_hertz": 1,
"heartbeat_interval_secs": 1,
"heartbeat_message": "{\"heartbeat\": [{}]}"
},
Simple Example
The following examples assume that the heartbeat message is configured for the LidarHub TCP stream. The example assumes that a heartbeat message contains a key called heartbeat, and does not process those frames.
The following example demonstrates how to connect to a TCP stream, which are open on ports 3302 and 3303. By default, the object_list data is streamed on port 3302, and the occupations data is streamed on port 3303. The object_list output is the object count data for the whole scene, while the occupations data is the zone occupation data.
For this example, note that the listening port can be changed with the PORT variable. The read_frames() function takes in a socket_client, as well as a Callable function. The function is expected to take in the JSON data as the first parameter, and then additional parameters can be passed in the same call to read_frames(). The example below passes the python print function, which will print the JSON data from the TCP stream.
#!/usr/bin/env python
"""
Example how to connect to a Ouster Gemini Detect TCP stream. Assumes that the object_list
is streaming on port 3302, and that the heartbeat is set to
"heartbeat_message": "{\"heartbeat\": [{}]}".
"""
import json
import socket
import ssl
from typing import Callable
# User defined variables. This is currently configured to listen to port
# 3302, which is by default is the `object_list` data.
HOST = "localhost"
PORT = 3302
# Ouster Gemini Detect defined variables
ENDIAN_TYPE = "big"
FRAME_SIZE_B = 4
ADDRESS = (HOST, PORT)
def recv(socket_client: ssl.SSLContext, num_bytes: int) -> bytearray:
"""
Helper Function to recv n bytes or return an empty byte array if EOF is
hit.
Args:
socket_client (ssl.SSLSocket): The socket connected to the TCP
stream.
num_bytes (int): The number of bytes to receive
Returns:
bytearray: The read bytes from the socket. Empty bytearray on
timeout or connection reset.
"""
data = bytearray()
# It is possible only part of the message is read. We loop until we
# received the whole message
while len(data) < num_bytes:
remaining_bytes = num_bytes - len(data)
try:
packet = socket_client.recv(remaining_bytes)
# If the socket times out or is reset, no data could be received.
except (socket.timeout, ConnectionResetError):
return bytearray()
# Append the data
data.extend(packet)
return data
def read_frames(
socket_client: ssl.SSLContext, callback_function: Callable, *args: tuple
) -> None:
"""
Indefinitely reads in frames of data. The first 4 bytes of the message is
expected to be the size of the message, and then that size will be read
immediately afterwards. Repeats until connection is lost.
Args:
socket_client (ssl.SSLSocket): The socket connected to the TCP
stream.
callback_function (Callable): The callback function to call when
receiving a valid set of data. The first parameter must be the
JSON from the TCP stream, and the remaining arguments will be passed
through args.
args (tuple): The remaining arguments of the callback_function.
"""
while True:
# Gets the size of the frame
frame_size_b = recv(socket_client, FRAME_SIZE_B)
# If the size is different than expected, we didn't receive a response.
# Return None, signalling either a failure to read the message, or that
# there were no present objects
if len(frame_size_b) == 0:
return
# Convert the byte data to an integer, representing the number of bytes
# of the message. Then read that size of data from the stream
frame_size = int.from_bytes(frame_size_b, ENDIAN_TYPE)
data = recv(socket_client, frame_size)
# Received no data, return None
if len(data) == 0:
return
data = json.loads(data.decode("utf-8"))
# If the dictionary contains "heartbeat" as a key, the message was a
# heartbeat. Continue to the next message. Note that this is
# configurable using the LidarHub settings.
if "heartbeat" in data.keys():
continue
callback_function(data, *args)
# Create the ssl context
ssl_context = ssl.SSLContext(ssl.PROTOCOL_TLSv1_2)
ssl_context.verify_mode = ssl.CERT_NONE
# Create the socket client
socket_client = ssl_context.wrap_socket(socket.create_connection(ADDRESS))
# This reads the frame data indefinitely. The first parameter is the socket.
# The next parameter is the callback function to pass the JSON data to.
# Additional parameters can be passed to be passed onto the function. The
# following line currently passes the JSON data to the print function. The
# following line can be updated with a custom callback function
read_frames(socket_client, print)
# Close the socket connection
socket_client.close()
Receiving objects from object_list
This is a continuation of the Simple Example. To connect to the
object_list, the following code block can be appended to the beginning of
the script, proceeding the imports. This parses the json data, and outputs the
object’s position if it matches the correct classification.
def print_objects_by_class(data: dict, classification: str) -> None:
"""
Callback function to print out the timestamp and position of any objects
that match the classification type. Must be listening to the object_list.
Args:
data (dict): Dictionary containing the batched object data.
classification (str): Classification to print out for
"""
# The data["object_list"] is a list containing the batched object_list data
# for the frames. The number of batched object_lists is configurable in the
# LidarHub settings using the `data_hertz` setting. See user manual for
# more details of the structure. The following checks in read_frames() will
# only enter this function if there is valid data. We use the first element
# in the list.
timestamp = data["object_list"][0]["timestamp"]
for object_dict in data["object_list"][0]["objects"]:
# Print out the object's position and its timestamp if the
# classification is correct
if object_dict["classification"] == classification:
print(f"time: {timestamp}\tPosition: {object_dict['position']}")
The read_frames() line in the original Simple Example should be
replaced with the following line, resulting in a print on any PERSON
classified objects. Notice that print_objects_by_class() takes in two
parameters, the first which must be the JSON data from the TCP stream, and the
second being the classification. The classification parameter is passed to the
read_frames() call, which forwards it to the print_objects_by_class()
call. The following line prints for any objects that meet the “PERSON”
classification.
read_frames(socket_client, print_objects_by_class, "PERSON")
Reading zone data from occupations
This is continuation of the Simple Example. The occupations by
default outputs to port 3303. Change the PORT variable to 3303
(PORT = 3303) within the Simple Example.
To connect to the occupations, the following code block can be appended to
the beginning of the script, and after the imports. This parses the json data,
and prints the object count within a specified zone. The zone is identified
using the zone_name parameter.
def print_occupation_count(data: dict, zone_name: str) -> None:
"""
Callback function to print out the object count within a specific zone. The
zone will be referenced by its name.
Args:
data (dict): Dictionary containing the batched object data.
classification (str): Classification to print out for
"""
queried_zone_data = {}
# The data["occupations"] is a list containing the batched occupations data
# for the frames. The number of batched occupations is configurable in the
# LidarHub settings using the `data_hertz` setting. See user manual for
# more details of the structure. The following checks in read_frames() will
# only enter this function if there is valid data. We use the first element
# in the list.
# This finds the queried zone's data
for zone_data in data["occupations"][0]["occupations"]:
if zone_data["name"] == zone_name:
queried_zone_data = zone_data
# If the dictionary is empty, return
if not queried_zone_data:
return
number_objects = len(queried_zone_data["objects"])
print(f"Number of objects in {zone_name}: {number_objects}")
The read_frames() in the original Simple Example should be replaced with the following line, resulting in a print when there are any objects
within the specified zone. Notice that print_occupation_count() takes in two parameters, the first which must be the JSON data from the TCP stream, and
the second being the zone name. The zone name parameter is passed to the read_frames() call, which forwards it to the print_occupation_count()
call. The below call uses Zone-0 as the zone’s identifying name.
read_frames(socket_client, print_occupation_count, "Zone-0")
Using Detect APIs (client-credentials)
The following example demonstrates how to communicate with Gemini Detect APIs. This example uses the client-credentials grant type, which is requires an RBAC client secret. Follow the steps in the Developer Access section to retrieve the client secret. This example finishes by accessing the Detect Perception API but, the same steps can be used to access any of the Detect APIs (see Ouster Gemini Detect API for more information).
import base64
import json
import requests
import urllib3
# Disable SSL verification as Gemini uses a self-signed certificate
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
class AuthenticatedAPI:
"""
A simple class to handle authentication and requests to a Gemini Detect instance.
Access tokens are automatically refreshed if they expire.
"""
def __init__(self, client_id, client_secret, token_url, base_url):
self.client_id = client_id
self.client_secret = client_secret
self.credentials = f"{client_id}:{client_secret}"
self.credentials = base64.b64encode(self.credentials.encode("utf-8")).decode(
"utf-8"
)
self.token_url = token_url
self.base_url = base_url
self.access_token = None
def login(self):
# Disable SSL verification as Gemini uses a self-signed certificate
response = requests.post(
self.token_url,
headers={
"Content-Type": "application/x-www-form-urlencoded",
"authorization": f"Basic {self.credentials}",
},
data={"grant_type": "client_credentials"},
verify=False,
)
if response.status_code == 200:
self.access_token = response.json().get("access_token")
return self.access_token
else:
raise Exception(
f"Failed to retrieve access token: {response.status_code} - "
f"{response.text}"
)
def request(self, method, endpoint, data=None):
headers = {"Authorization": f"Bearer {self.access_token}"}
url = f"{self.base_url}/{endpoint}"
# Disable SSL verification as Gemini uses a self-signed certificate
response = requests.request(
method, url, headers=headers, data=data, verify=False
)
if response.status_code == 401:
# If access token is denied, refresh it and retry the request
self.login()
headers["Authorization"] = f"Bearer {self.access_token}"
# Disable SSL verification as Gemini uses a self-signed certificate
response = requests.request(
method, url, headers=headers, data=data, verify=False
)
if response.status_code == 200 or response.status_code == 201:
return response.json()
else:
raise Exception(f"Request failed: {response.status_code} - {response.text}")
def get(self, endpoint):
return self.request("GET", endpoint)
def post(self, endpoint, data):
return self.request("POST", endpoint, data)
def put(self, endpoint, data):
return self.request("PUT", endpoint, data)
def delete(self, endpoint):
return self.request("DELETE", endpoint)
# Usage example
if __name__ == "__main__":
# Client ID is always "detect-client"
client_id = "detect-client"
# Client secret is retreived from the Keycloak Admin Console -> Clients(side bar) ->
# detect-client(clients list) -> Credentials (tab)
client_secret = "dcPgSCJVAbfGw1nOsV3coROGEtOgXp42"
# Base URL is the IP address or domain name of the server hosting Gemini Detect
base_url = "https://chorizo.local"
# Token URL should always be as shown below
token_url = f"{base_url}/auth/realms/detect/protocol/openid-connect/token"
api = AuthenticatedAPI(client_id, client_secret, token_url, base_url)
# Example request. This will throw an exception if the login fails (credentials/URL
# is incorrect).
try:
response = api.get("perception/api/v1/about")
print(json.dumps(response, indent=4))
except Exception as e:
print(f"Error: {e}")
Sensor Placement
The goal of sensor placement can vary depending on usage but typically involves maximizing the number of returns on objects of interest. This should take into account static obstacles, for example buildings, traffic light or furniture as well as dynamics obstacles such as vehicles or pedestrians.
For some use cases single sensors are appropriate but for others multiple sensors are required. Sensors should be placed to maximize the number of returns on objects of interest.
Tips for individual sensor placement
Sensor field of view and maximum range should be taken into account. The maximum tracking range is less than the maximum range of the sensor due to a minimum number of point on targets in order to indentify it.
Suggested tracking range for Rev6 sensors are. * OS-O: 25 meters * OS-1: 45 meters * OS-2: 60 meters
Sensor must mounted on static position. Sensor movement will result in poor tracking. Typically mounting on poles or building works, but be carefull with traffic pole supporting arms because they may move in the wind.
Ouside sensors should be placed higher that typical maximum vehicle heights (3m as a baseline). Higher sensor mounting height does result in wider blind spots around non dome sensor so multiple sensors may be required if a buffer zone around the sensor is unacceptable.
Inside sensors should be place on ceilings or above obstacles if possible.
Sensors may be angled or placed flat. Angled can get better coverage in one direction, but results in larger blind spots behind the sensor.
Take into account the sensor FOV’s. The FOV’s of sensors are: * OS-0 += 45 degrees from horizontal * OS-1 +- 22.5 degrees from horizontal * OS-2 += 11.25 degrees from horizontal
Multi-Sensor Usage
Multiple sensors can help improve coverage in different monitoring situations:
They can avoid blindspot, for example there is typically a blindspot under sensors and on multi-lane roads large vehicles may shield smaller vehicles from view.
They also increase coverage area, either by being seperated geographicaly or angularily.
Data from multiple sensors is fused so that if an object is seen by multiple sensors it will have improved accuracy.
Procedure for planning multi sensor locations
Start with a map of floorplan of the area. A satellite view of the area is ideal if it is up to date because it includes locations of most obstacles.
Figure out the priority areas of interest on the map. That may be a single area or the whole map. Draw those areas on the map.
It is easiest to start by assuming the sensor are placed flat. Depending on the sensor height a X by X donut can be drawn on the map. Look for ideal placement locations with good views in many directions. These may vary depending on already placed poles, walls or other features.
For an OS-0, the circle should have an outer radius of ~25 m (max tracking range) and an inside radius of the sensor height.
For an OS-1, the circle should have an outer radius of ~45 M (max tracking range) and an inside radius of 2.4 times the sensor height.
For an OS-2, the circle should have an outer radius of ~60 M (max tracking range) and an inside radius of 5 times the sensor height.
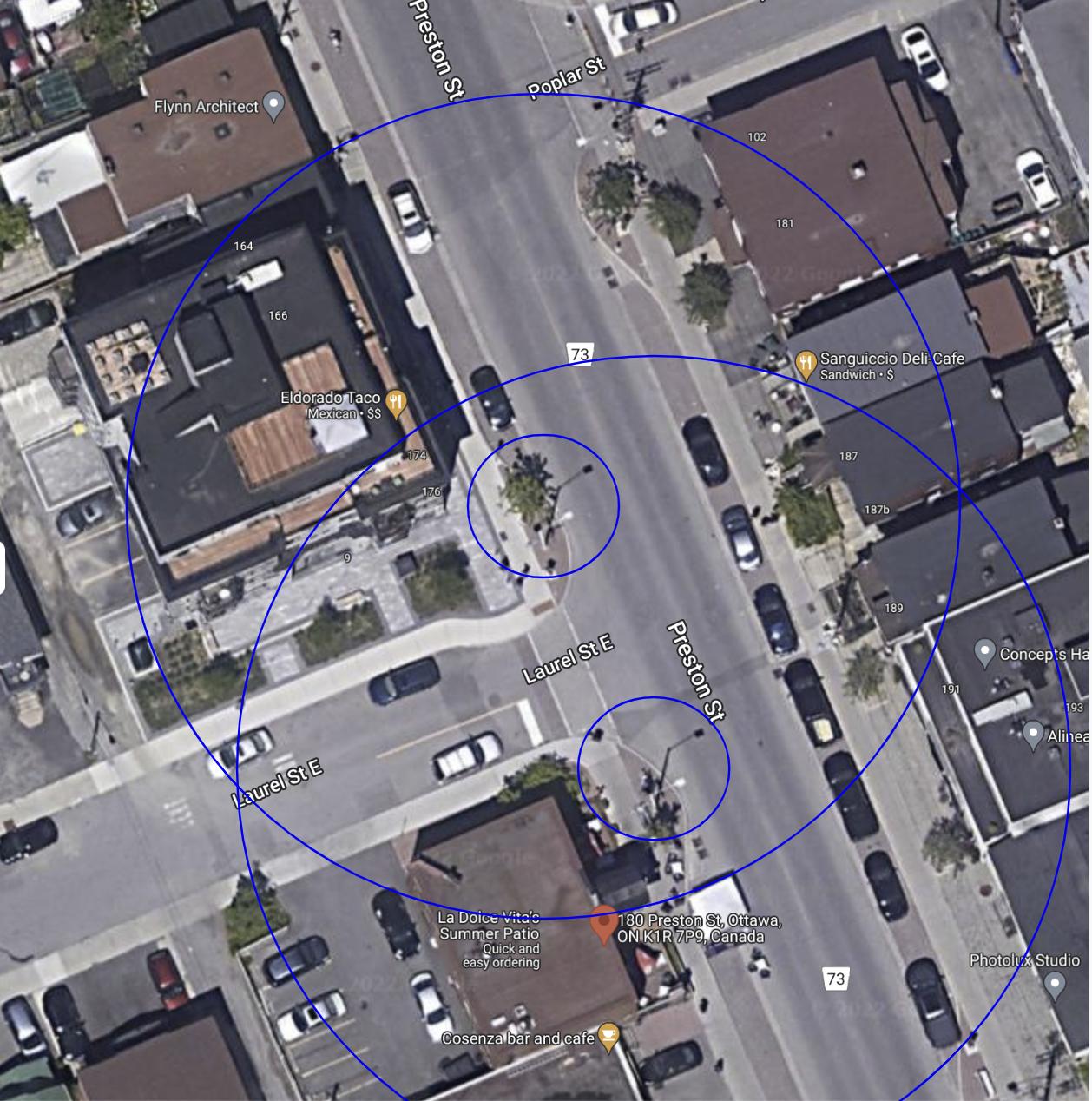
Example of sensor coverage on a map
This will give an initial ideal of what can be covered. Move the sensor around to try to figure out good placement. If you need continuous coverage of the whole area sensors will have to cover the blind spots of each other. If good coverage cannot be obtained with flat sensors they can be tilted. This will reduce the inner radius on the ground in one direction but increase it in the other.
Setting up DL AOD
When using Gemini Detect (2.8 and prior) Deep Learning, users need to configure an area of detection called the DL AOD. The DL AOD is the area where Gemini Detect’s deep neural network will look for objects in. The larger the area, the more GPU computation Gemini Detect requires. Therefore, it’s recommended to make the DL AOD just large enough to cover your desired area. This DL AOD needs to be configured for each sensor.
Note
This DL AOD is not applicable when Gemini Detect is running without Deep Learning.
To configure the DL AOD, navigate to the Setup Page and click the DL tab.
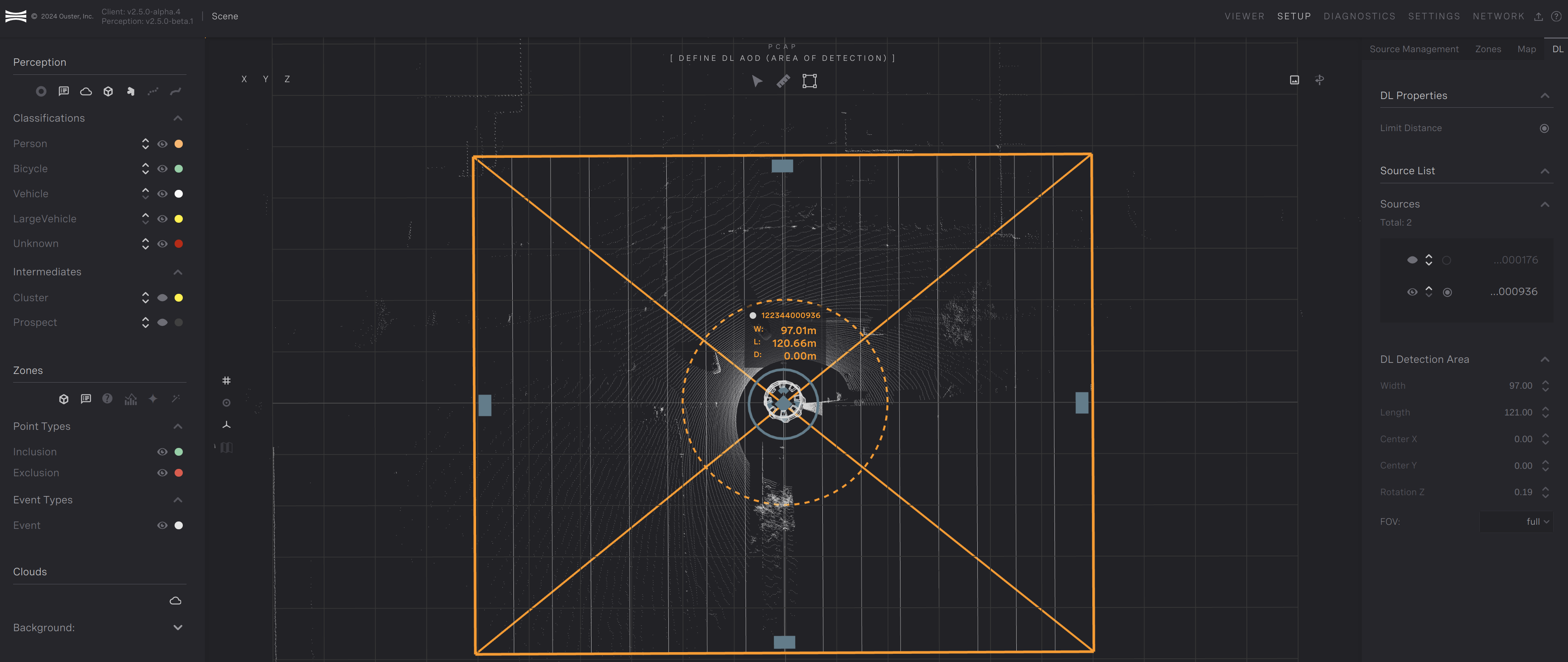
DL tab
The DL AOD needs to be configured for each sensor separately. Once the sensor is selected in the Source List on the right pane, the DL AOD box will appear with controls for moving it around. The area within the AOD that will be used is lined as shown in the diagram. You can adjust:
The length and width of the box with the side buttons on the edge of the DL AOD box. Drag the side bars to resize the box as desired.
The orientation of the AOD. Click and hold the mouse on the solid circle to rotate.
In multi sensor inference mode enabling or disabling the sensor as a primary source for ML.
The position of the center of the AOD. Click on the sensor or the translation buttons and drag the AOD.
The FOV of the AOD. This can be changed in the drop down menu in the DL Detection Area section. Selecting “front” will operate on half the area. This can help minimize the area to keep processing fast while keeping the center of the AOD close to the sensor.
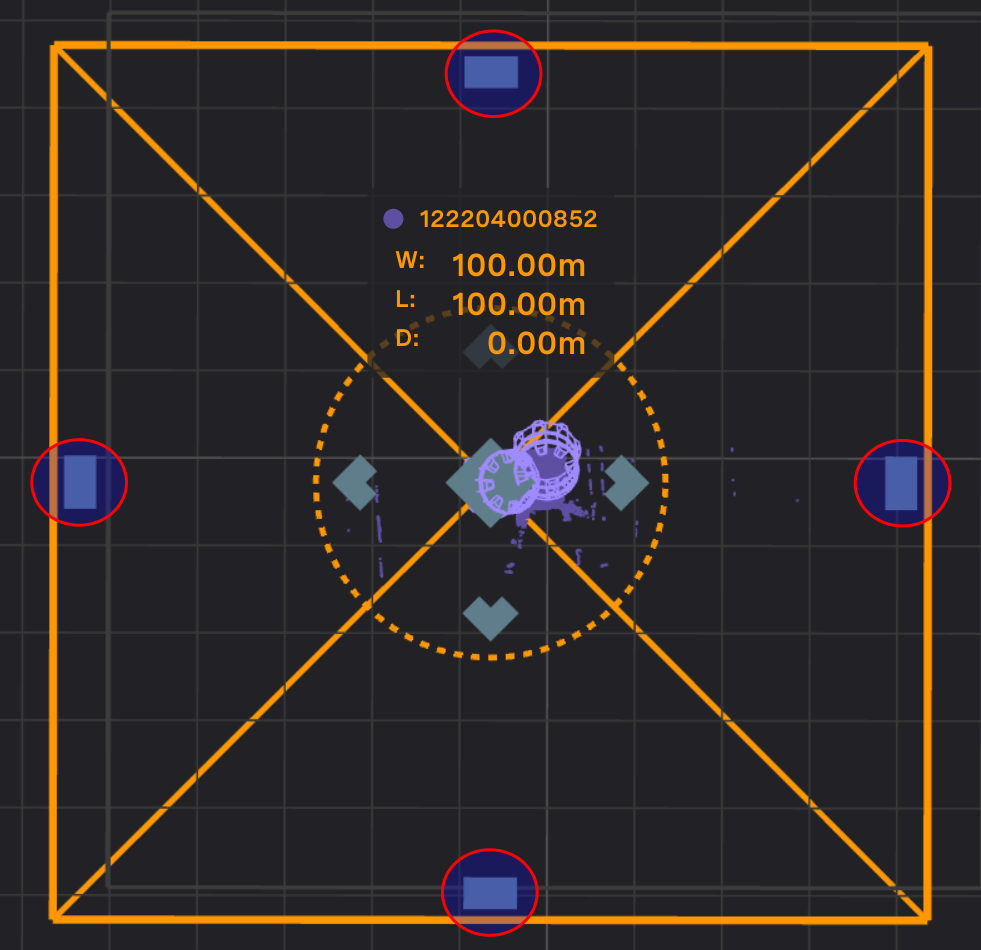
Side bars |
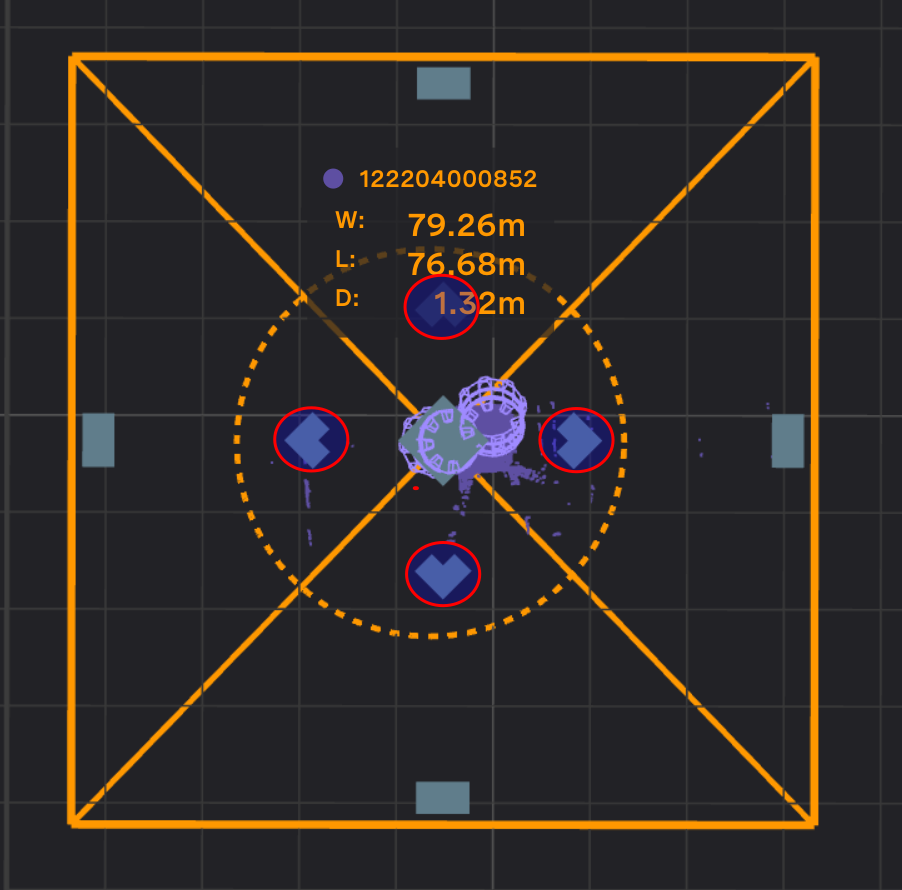
Translation buttons |
Gemini Detect requires the DL AOD to be positioned within 20m of the sensor position. The dotted circle indicates this constraint. If the user tries to place the DL AOD position more than 20m away from the sensor position, the DL AOD position will snap back to within 20m.
Objects will not be detected outside the DL AODs when Gemini Detect is configured for Deep Learning. It’s recommend to have at least 2m of overlap between DL AODs of different sensors to ensure objects moving between lidar FOV will be continually tracked.
Multi Sensor Inference
DL profiles can operate in the two modes outlined below. Control of the mode used can be set in settings under multi_sensor_inference.
Single Sensor Inference Mode:
This is the default for all DL profiles. Detection operates on each sensor independently and then detection results are fused. It works well for high speed speed vehicles since skew on a single sensor is limited. Choosing the AOD’s is typically based on choosing the area that each sensor see’s. The user needs to draw the AOD’s such that there is lots of overlap between sensors.
Multi Sensor Inference Mode
In this mode each sensor has a primary AOD that it operates on, and data from each other sensor is processed within the AOD as well. This works well for slow moving areas where skew between sensors is minimized or if the sensors can be synced in time with PTP to see the same objects at the same time.
For multi-sensor inference mode, the AOD’s of all the sensors combined should cover the monitored area. If sensors are placed far apart, then they should each have a seperate AOD, with an overlap of approximately 10 m between the AOD’s. 10 m ensures the large vehicles aren’t fully split between zones and also minimizes extra processing. If any sensors are placed very close together they should use a single AOD by creating an AOD for one of the sensors and disable DL processing on the other sensor.
General Alignment Procedure
These are the general steps for LiDAR alignment.
It is recommended to align a single sensor at a time. Toggle the visibility of other clouds to only show a single visible cloud. Select that point cloud in the right panel. The alignment tool will appear.
Align the the transform with the positive z-axis pointing in the up direction relative to gravity. Refer to section IMU Pose and Pitch and Roll Alignment for this procedure.
Use the alignment tool to adjust the yaw and translation for the point cloud. The position and yaw of a single point cloud can be set arbitrarily based on preference. It is recommended to set the point cloud’s ground/floor inline with the x-y plane. This will allow the user to easily see the pitch and roll error of the point cloud, if the ground plane is flat. For Gemini Detect Deep Learning, this is a requirement. The deep learning model is trained based on the ground being at z = 0. If the ground is not leveled with z = 0, you will likely experience poor object detection performance.
If the lat/long of the world reference frame is configured through the
Maptab, use the map underlay as a real-world reference for outdoor scenes.Click Save Pose to save the cloud’s transform to disk. This will apply the transform in the viewer page.
Multiple LiDAR Installations
The following steps are for multiple LiDAR installations and are a continuation of the previous steps. The point clouds between LiDARs must be properly aligned together for cohesive object tracking.
Show the visibility of a single point cloud which overlaps with the originally aligned reference cloud. If the two scenes do not have overlapping field of views, it’s difficult to align the two clouds.
Align the cloud with the positive z-axis pointing in the up direction relative to gravity using the steps outlined in the section IMU Pose and Pitch and Roll Alignment.
Roughly align the cloud to the originally set cloud using the alignment tool. Typically, the x, y and z translation will need to be adjusted, as well as the yaw. Use physical references within the two scenes to align the two clouds together.
Refer to section Automatic Alignment Tool and align a reference cloud to the current unaligned cloud. The reference cloud should be an already aligned cloud that has the most overlapping features with the unaligned cloud.
Repeat these steps for any additional sensors to be added to the scene.
Changing Certificate on Edge Processor
Using a custom certificate
The system will create self signed certificate by default on first startup to support https/ssl.
However, since it is self signed this means that users connecting will get a warning that the site it not secure and that they can choose to make an exception. To not require this exception users can upload a certificate for the system to use.
To do this:
Request a certificate signing request (CSR) from the system though the rest interface at: api/v1/csr/<DOMAIN> The DOMAIN should matched the DOMAIN section of the served url.
Use the CSR to create a certificate for the system from a CA. This can either be done through a public certificate authority (CA), in which case follow their instructions or through a organizations CA. For development tests a linux CA can be created using instructions on https://deliciousbrains.com/ssl-certificate-authority-for-local-https-development/
Upload the generated certificate to the system using the rest interface at perception/api/v1/certificate. If the certificate is not valid it will be rejected.
If a local/organizational CA is used and has not been previously added, add it to the computer store. Follow instruction for your OS and/or browser.
The site will no longer show up as insecure.
Perception Tuning
default_settings
These are settings that are optimal for outdoor use case, specifically the tracking of vehicles, along with people. Some of the key features that are used:
Failed point logic. A failed point is a return we usually receive, but did not receive within the LiDAR frame. This is required for black car clustering. There are circumstances were we only see the hub caps of a car, which are very far apart, and can only be clustered together using failed points.
We favour larger clusters to cluster the majority of cars together.
Setting |
Description |
Default |
|---|---|---|
/lidar_pipeline/ cluster/bbox_algorithm |
The bbox that will fit to the object. We need tight bounding boxes to better track vehicles, because we use that box for tracking. This algorithm works well to conform to the shape of the vehicle. |
“brute_force” |
/lidar_pipeline/ range_image_clustering/ propagate_using_failed_return |
Asserts whether to bridge failed points for clustering. Since failed point logic is primarily for black vehicles, this is essential for good vehicle tracking. |
true |
/lidar_pipeline/ range_image_clustering/ distance_threshold |
The required distance threshold between adjacent points in the range image that must be met, for both points to be considered part of the same cluster. This will cluster more things together, resulting in larger clusters. This is optimal to avoid large vehicles clustering together |
0.40 |
/lidar_pipeline/ range_image_clustering/ max_dynamic_distance_threshold |
This is the max distance threshold we use when bridging failed points, in metres. When we cluster over failed points, we increase the distance threshold for associating 2 points to the same cluster. We also need to increase the distance threshold. The distance threshold for clustering becomes (distance_threshold) * (n + 1), where n is the number of failed points that were bridged. We cap this to a maximum of 3 metres. |
3.0 |
/lidar_pipeline/ vertical_cluster_merge/ max_merge_dimension |
Vertical cluster merge merges clusters that overlap, or nearly overlap. This specific setting is the maximum size that the candidate merged cluster is allowed to be. If the merged cluster is larger than this, the merge is rejected. For vehicle cases, we need to allow large objects, so the default is 10.0 m. |
10.0 |
/object_pipeline/ vertical_cluster_merge/ max_merge_dimension |
The same description as above, however this is the merging of clusters from multiple pipelines. |
10.0 |
Setting |
Description |
Default |
/object_pipeline/ data_association/ distance_threshold |
The max distance we check between the predicted position (from the KF) and the measured centre position of the cluster in metres. The larger the distance, the longer the computation. When we begin tracking an object, the KF has a bad estimate of the velocity, and will assume that it has not moved within the first frame (since we do not know which direction it is going from a single frame). Thus, this threshold should be the max distance that you expect the object to move within a single frame. |
10.0 |
/object_pipeline/ classifier/algorithm |
The classifier to use. We set this naive_bayes, which allows the classification of people, bicycles, vehicles, and large_vehicles. |
naive_baye |
pedestrian_settings
Settings to track only people. In this case, the classification of vehicles are disabled.
Setting |
Description |
Default |
Modified |
|---|---|---|---|
/lidar_pipeline/ cluster/bbox_algorithm |
The bbox that will fit to the object. Since tight fitting boxes are not vital to tracking people, we use PCA since it is a very efficient algorithm. |
“brute_force” |
“pca” |
/lidar_pipeline/ range_image_clustering/ propagate_using _failed_return |
Asserts whether to bridge failed points for clustering. Since failed point logic is primarily for black vehicles, this is unnecessary, and will only cause the over-clustering of people. |
true |
false |
/lidar_pipeline/ range_image_clustering/ distance_threshold |
The required distance threshold between adjacent points in the range image that must be met, for both points to be considered part of the same cluster. |
0.40 |
0.30 |
Setting |
Description |
Default |
Modified |
/lidar_pipeline/ vertical_cluster_merge/ max_merge_dimension |
Vertical cluster merge merges clusters that overlap, or nearly overlap. This specific setting is the maximum size that the candidate merged cluster is allowed to be. If the merged cluster is larger than this, the merge is rejected. For people cases, we expect much smaller clusters. This setting can be lower. |
10.0 |
1.0 |
/object_pipeline/ vertical_cluster_merge/ max_merge_dimension |
The same description as above, however this is the merging of clusters from multiple pipelines. |
10.0 |
1.0 |
/object_pipeline/ data_association/ distance_threshold |
The max distance we check between the predicted position (from the KF) and the measured centre position of the cluster in metres. The larger the distance, the longer the computation. When we begin tracking an object, the KF has a bad estimate of the velocity, and will assume that it has not moved within the first frame (since we do not know which direction it is going from a single frame). Thus, this threshold should be the max distance that you expect the object to move within a single frame. |
10.0 |
1.5 |
/object_pipeline/ classifier/algorithm |
The classifier to use. We set this heuristic, which only classifies people and vehicles. We then change some parameters to assume that everything is a person. |
naive_bayes |
heuristic |
/object_pipeline/ classifier/heuristic/ person_max_speed |
This prevents any vehicle classifications. This is the max speed a person can move in m/s. |
4.1 |
100.0 |
Configuring Ethernet Ports Using Netplan
Netplan is the network configuration tool used in modern Ubuntu-based systems to configure network interfaces. Below is an example configuration file that configures one Ethernet interface to use DHCP, and all others to use static IP addresses. This configuration file is for a server that provides DHCP services for multiple subnets.
network:
renderer: networkd
ethernets:
eno1:
dhcp4: true
dhcp6: true
link-local:
- ipv4
- ipv6
optional: true
nameservers:
addresses:
- 8.8.8.8
- 8.8.4.4
enp3s0:
addresses:
- 10.125.40.1/24
ignore-carrier: true
optional: true
enp2s0f0:
addresses:
- 10.125.20.1/24
ignore-carrier: true
optional: true
enp2s0f1:
addresses:
- 10.125.21.1/24
ignore-carrier: true
optional: true
enp2s0f2:
addresses:
- 10.125.22.1/24
ignore-carrier: true
optional: true
enp2s0f3:
addresses:
- 10.125.23.1/24
ignore-carrier: true
optional: true
version: 2
To apply this configuration:
Save the configuration to a file in
/etc/netplan/, for example,/etc/netplan/01-customer-config.yamlValidate the configuration:
sudo netplan try
If everything looks good, apply the configuration:
sudo netplan apply
To verify the configuration, check the interface status:
ip addr
Key configuration elements:
dhcp4: trueanddhcp6: trueenable DHCP for IPv4 and IPv6 respectivelyoptional: trueallows the system to boot even if the interface is not connectedignore-carrier: trueconfigures the interface even if no carrier is detectednameserverssection specifies DNS servers to use. Note that many DHCP servers will provide this information, so it is not strictly necessary to specify it here in most cases.
DHCP Server Configuration
A sample dhcpd.conf file is shown below for the ISC dhcpd server. This configuration file is for a server that provides DHCP services for multiple subnets. On Ubuntu systems, this file normally resides in /etc/dhcp/dhcpd.conf.
# dhcpd.conf
#
# Sample configuration file for ISC dhcpd
#
# Attention: If /etc/ltsp/dhcpd.conf exists, that will be used as
# configuration file instead of this file.
#
# option definitions common to all supported networks...
option domain-name "ouster.io";
default-lease-time 600;
max-lease-time 7200;
# The ddns-updates-style parameter controls whether or not the server will
# attempt to do a DNS update when a lease is confirmed. We default to the
# behavior of the version 2 packages ('none', since DHCP v2 didn't
# have support for DDNS.)
ddns-update-style none;
# If this DHCP server is the official DHCP server for the local
# network, the authoritative directive should be uncommented.
authoritative;
# Configuration for the following interfaces
DHCPDARGS="enp2s0f0 enp2s0f1 enp2s0f2 enp2s0f3 enp3s0";
subnet 10.125.20.0 netmask 255.255.255.0 {
range 10.125.20.2 10.125.20.22;
}
subnet 10.125.21.0 netmask 255.255.255.0 {
range 10.125.21.2 10.125.21.22;
}
subnet 10.125.22.0 netmask 255.255.255.0 {
range 10.125.22.2 10.125.22.22;
}
subnet 10.125.23.0 netmask 255.255.255.0 {
range 10.125.23.2 10.125.23.22;
}
subnet 10.125.40.0 netmask 255.255.255.0 {
range 10.125.40.2 10.125.40.22;
}
# Use this to send dhcp log messages to a different log file (you also
# have to hack syslog.conf to complete the redirection).
#log-facility local7;